Overall Pipeline
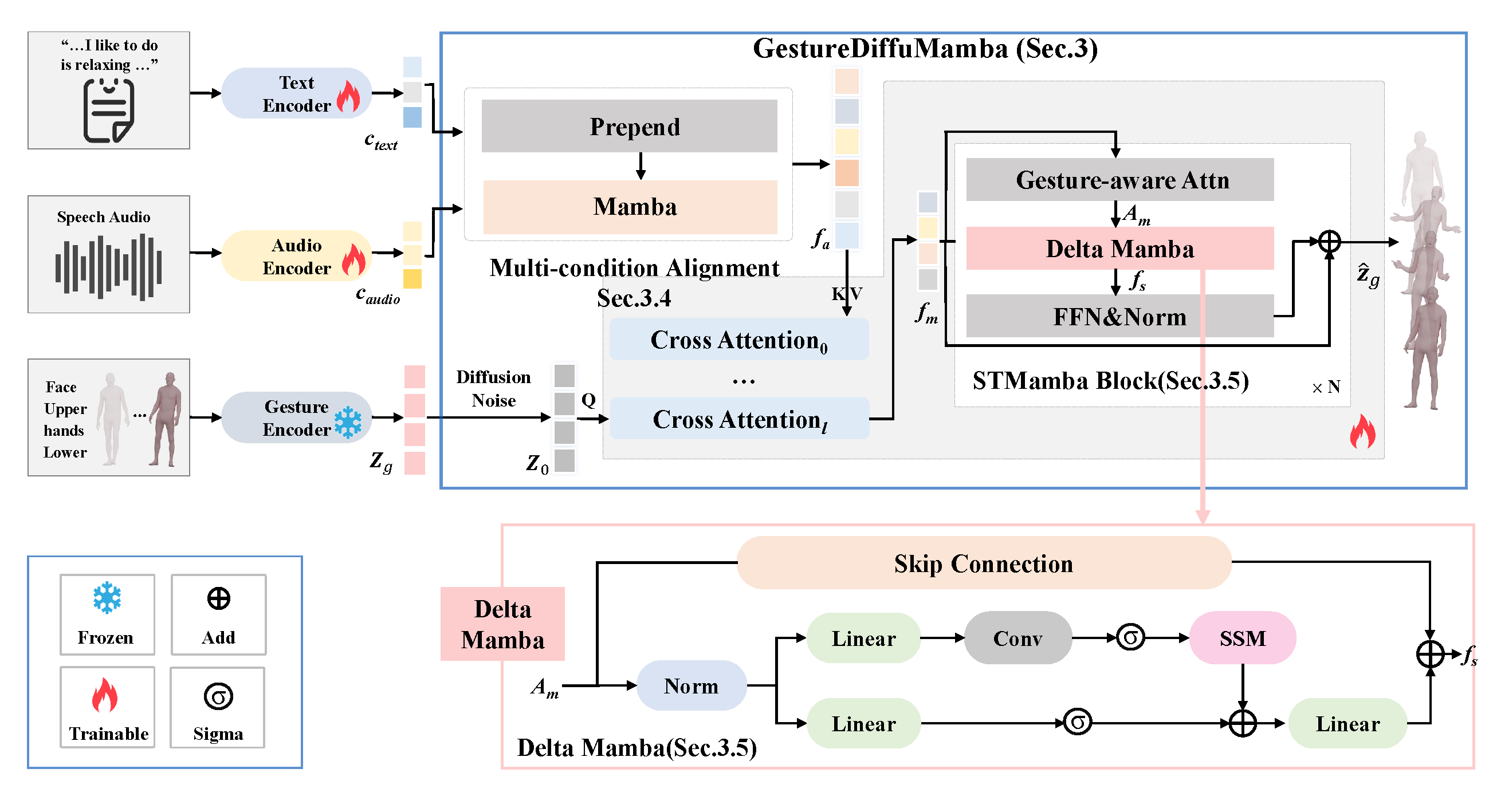
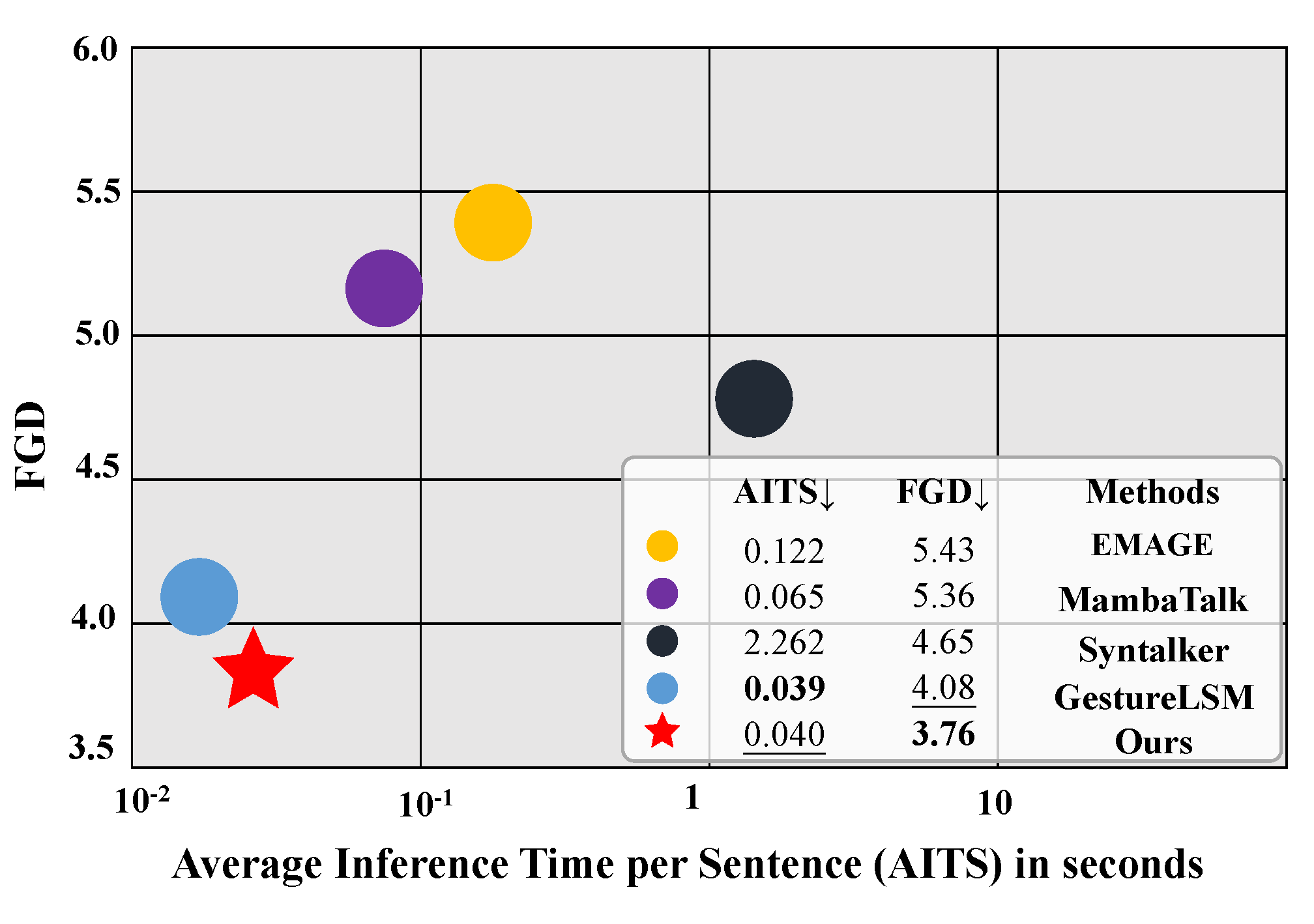
As human-avatar interaction becomes increasingly central to virtual communication, the demand for generating expressive, synchronized, and diverse co-speech gestures is growing rapidly. Existing methods, often based on attention architectures, struggle to jointly capture semantic intent from multimodal inputs and generate fluid, temporally coherent full-body motion. To overcome these limitations, we introduce GestureDiffuMamba, a diffusion-based framework designed to unify multimodal fusion and spatiotemporal gesture modeling. GestureDiffuMamba employs a novel Multi-condition Alignment module that integrates Mamba with cross-attention to align audio and textual signals in a temporally sensitive manner. To handle the distinct nature of spatial and temporal motion features, we design the STMamba block, which combines Gesture-aware Attention for body-part structural correlation and a residual-enhanced Delta Mamba for semantic temporal dynamics. This hybrid architecture ensures that generated gestures are both expressive and physically coherent. By leveraging diffusion modeling and efficient state-space dynamics, our method enables the synthesis of natural, diverse, and semantically aligned gestures in complex speech scenarios. Extensive experiments on the BEAT2 dataset demonstrate that GestureDiffuMamba outperforms state-of-the-art baselines in fidelity, diversity, and audio-motion synchronization, offering a robust solution for realistic gesture generation.